Introduction to Hash Table
----------------------------------------------------------------------
Hashing is a part of Data Structure that maps certain values with keys. These keys are shorter and easier to read than the value itself, so it is used to increase efficiency when referring to a value. How much more efficient it becomes will depend on the type of hashing that is used. A Hash Table is an array where the hash keys are stored. The method used to create the Hash Table is called Hash Function.
Example of Hash Table:
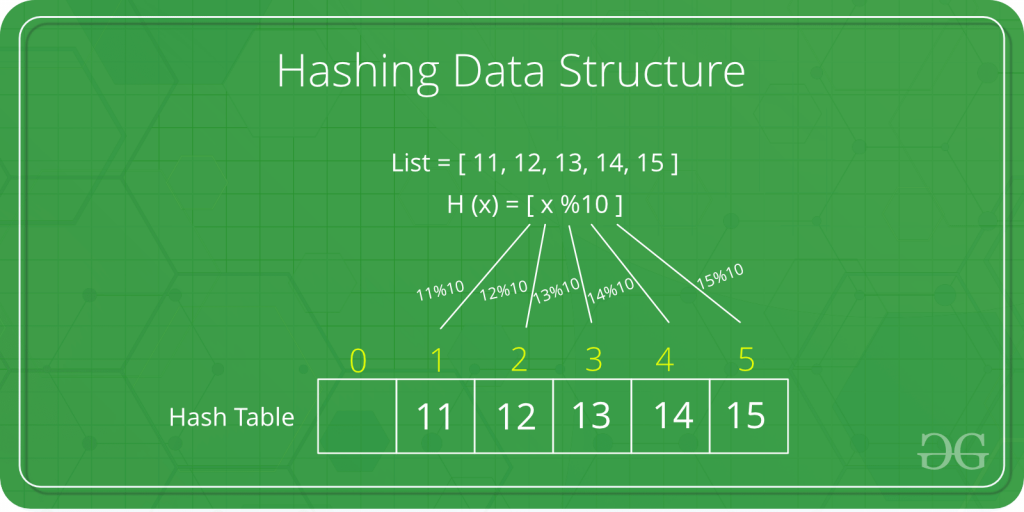
Hash Functions
----------------------------------------------------------------------
There are a very wide variety of Hash Functions, but on this article, I will only explain about Mid-square, Division, Folding, Digit Extraction and Rotating Hash.
Mid-square is a Hash Function where the value is squared, and then taking the middle part of the squared value as the key. For example, with a value of 2175, it will be squared to become 4730625. We take the middle part, which is 306, to become the key. In Mid-square, collision has a low probability of occurring, but still noticeable. An example is for values 2000 and 9000, both will result in a key of 000. It is also important to remember that squaring a value may cause overflow. If an overflow occurs, it can be fixed by using long long integer data type or using string as multiplication.
Division (or also known as Mod method) is a Hash Function where the key is Value % (modulus) Constant. For example, with a value of 64971 % 97, it will result in a key of 78. It is known that Division works best with a prime number as its modulus constant. The larger the prime number, the better. Collision can still occur with any constant, for example 472819 and 740166 has the same key value, being 38.
Folding is a Hash Function where the value is partitioned, then the parts are added to form the key. For example, with a value of 56143, the value is split into 56, 14 and 3, then added to become 73. Folding is relatively fast, and also prevents Collision quite well, but not completely. For example, 12356 and 48301 both has a key of 71.
Digit Extraction is a Hash Function where digits of the value is taken to create a shorter value as the key. For example, with a value of 3728192, we take the first, third, fifth and seventh value to form 3212 as the key. Collision can occur if the digits taken are the same. For example, the values 12345 and 18355 would have the same keys.
Rotating Hash is a Hash Function where a key from another Hash Function has its rightmost digit shifted onto the leftmost digit. For example, a key of 473 becomes 347 after Rotating Hash. Rotating hash helps with preventing Collisions.
Collision Handling
----------------------------------------------------------------------
In Hashing, there is a very real possibility that Hash Functions has certain values with the same keys. This is called Collision. There are two ways to handle a collision, those being Chaining and Open Addressing.
Chaining makes use of Linked Lists so that when a Collision occurs, the key for that value will be stored in the next node. This has the disadvantage of using larger amounts of memory, and is more suitable for larger programs.
Open Addressing or Linear Probing is when a Collision occurs, the key for a certain value will change by a certain amount, such as +1, until a Collision no longer occurs. This has the disadvantage of potentially making the Hash Table hard to read.
Introduction to Tree
----------------------------------------------------------------------
A Tree is a hierarchial Data Structure, which allows for faster and easier access. There are a number of terminologies that are used for Trees, the most basic of them being Node and Edge. Values are contained by Nodes and Nodes are connected by Edges. Here is an example of a Tree:
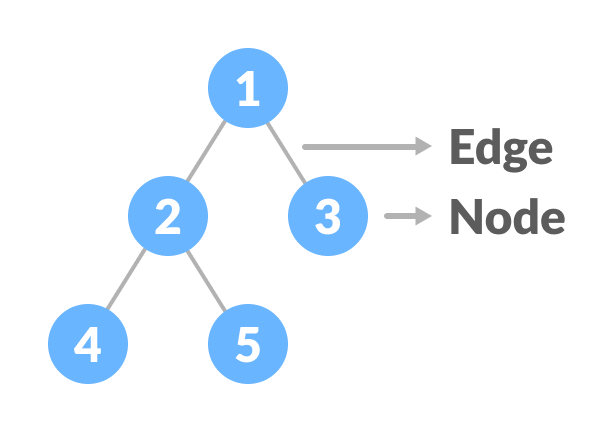
Other than those, Root describes the topmost Node of a Tree, a Child is a Node that branches from another Node, a Leaf is a Node that doesn't have any child and a Forest is a set of disjointed trees. A Node has Height/Depth and Degree. Height/Depth describes the number of edges towards/from the deepest leaf. The Height/Depth for a Root Node is also the Height/Depth for the Tree. Degree describes the number of branches in the Node.
Binary Tree
----------------------------------------------------------------------
Binary Tree is a Tree where each Node has a maximum of two Children. Each Node contains a data, a left pointer and a right pointer. In C, it would look like this:struct node {
int data;
struct node *left;
struct node *right;
};
Types of Binary Trees
----------------------------------------------------------------------
Binary Trees have multiple variations, the most common of them being Perfect, Complete, Skewed and Balanced Binary Trees.Perfect Binary Tree or Full Binary Tree is a Binary Tree where every node except for the leaves has two children. In a Perfect Binary Tree, you can count the amount of leaves by adding the number of Nodes before it + 1.
Complete Binary Tree is a Binary Tree where every level of the tree, except for maybe the last level, has the maximum amount of Nodes. A Perfect Binary Tree is always also a Complete Binary Tree.
Skewed Binary Tree or Degenerate Binary Tree is a Binary Tree where every Node has at maximum one child.
Balanced Binary Tree is a Binary Tree where none of the leaves are shorter or further than any other leaves from the root.
Expression Tree is a Binary Tree where every leaf contains an operand and every other node contains an operator. Expression Trees can be used for Prefix, Postfix and Infix Traversals.
Threaded Binary Tree is a Binary Tree variant where Node pointers previously pointing towards NULL, now points to a previous Node.
References:
https://www.geeksforgeeks.org/hashing-data-structure/
https://www.geeksforgeeks.org/mid-square-hashing/
https://www.baeldung.com/folding-hashing-technique
http://blog4preps.blogspot.com/2011/07/hashing-methods.html
https://eternallyconfuzzled.com/hashing-c-introduction-to-hashing
https://www.programiz.com/dsa/trees
https://www.geeksforgeeks.org/binary-tree-data-structure/
https://www.geeksforgeeks.org/threaded-binary-tree/
https://greatnusa.com/theme/trema/view.php?id=178