Introduction to Binary Search Tree
----------------------------------------------------------------------
A Binary Search Tree is a Data Structure, being a variation of Binary Tree. It is essentially a sorted version of Binary Tree, and some people refer to it as such. A Binary Search Tree has these following properties;- The left subtree of a node contains only nodes with keys lesser than the node’s key.
- The right subtree of a node contains only nodes with keys greater than the node’s key.
- The left and right subtree each must also be a binary search tree.
A Binary Search Tree has a search time of 0(log(n)). A Binary Search Tree has the advantages of having quick searching, insertion and deletion due to being sorted.
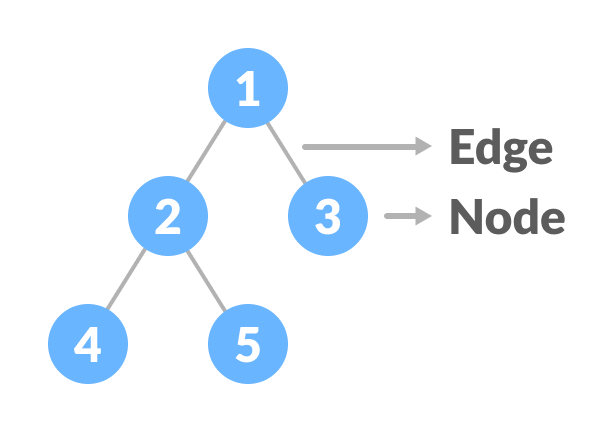
Example of a Binary Search Tree:

Search Operation
----------------------------------------------------------------------
When performing a Search in Binary Search Tree, the program will first check the root value and then go from there until it finds the key value. If the key value smaller than the root or parent value, it will check the left-hand side, and if it's larger than the root or parent value, it will check the right-hand side.Example of a Binary Search Tree Searching function in C:
struct node* search(struct node* root, int key)
{
// Base Cases: root is null or key is present at root
if (root == NULL || root->key == key)
return root;
// Key is greater than root's key
if (root->key < key)
return search(root->right, key);
// Key is smaller than root's key
return search(root->left, key);
}
The function employs simple recursion applications to perform the search.
Insertion Operation
----------------------------------------------------------------------
To perform an insertion in Binary Search Tree, the program will first check whether the tree is empty or not. If it's empty, then the current key value will become the root of the tree. If it's not empty, the program will keep checking either left for values smaller than the parent node, or right for values larger than the parent node until it finds an empty node.Example of a Binary Search Tree Insert function in C:
struct node* insert(struct node* node, int key)
{
/* If the tree is empty, return a new node */
if (node == NULL) return newNode(key);
/* Otherwise, recur down the tree */
if (key < node->key)
node->left = insert(node->left, key);
else if (key > node->key)
node->right = insert(node->right, key);
/* return the (unchanged) node pointer */
return node;
}
The function first looks whether the current node is empty or not. If it's empty, the function ends there and the key will be inserted in that node. Otherwise, it will do a recursion in a similar fashion to the Search function until it finds an empty node.
Deletion Operation
----------------------------------------------------------------------
To perform a deletion in Binary Search Tree, the program will first check whether the root has any value or not. If it doesn't, then the function will end without doing anything. Otherwise, the function will check whether the key value is smaller, larger or is contained within the node, starting from the root.Once the function has successfully found the node that is going to be deleted, the function performs a selection to determine how many child the node has. If the function finds it to either have no child or only one child, the function will move the other node (or if the other node is also NULL, do nothing) to the selected node. If the node does have two children, it will find the 'inorder successor', a node with the smallest value from its right-hand side. After that, it will copy the inorder successor to the selected node, then delete the node that used to house the inorder successor.
Example of a Binary Search Tree Delete function in C:
struct node* deleteNode(struct node* root, int key)
{
// base case
if (root == NULL) return root;
// If the key to be deleted is smaller than the root's key,
// then it lies in left subtree
if (key < root->key)
root->left = deleteNode(root->left, key);
// If the key to be deleted is greater than the root's key,
// then it lies in right subtree
else if (key > root->key)
root->right = deleteNode(root->right, key);
// if key is same as root's key, then This is the node
// to be deleted
else
{
// node with only one child or no child
if (root->left == NULL)
{
struct node *temp = root->right;
free(root);
return temp;
}
else if (root->right == NULL)
{
struct node *temp = root->left;
free(root);
return temp;
}
// node with two children: Get the inorder successor (smallest
// in the right subtree)
struct node* temp = minValueNode(root->right);
// Copy the inorder successor's content to this node
root->key = temp->key;
// Delete the inorder successor
root->right = deleteNode(root->right, temp->key);
}
return root;
}
This function is fairly complex until you analyze and break down what the function does. I recommend looking at the code and explanation at the same time.
Deletion Operation
----------------------------------------------------------------------
That marks the end of this article. Thank you for having stuck to the end.References:
https://www.geeksforgeeks.org/binary-search-tree-data-structure/
https://www.programiz.com/dsa/binary-search-tree